If you’ve never used Dianping, think Yelp—but shinier, angrier, and far more dominating with the fate of restaurants in China. It’s the platform people turn to when deciding whether some ¥68 hotpot buffet would be a delicious meal or a strict no-no.
Naturally, the platform holds immense power. A single low rating can haunt a restaurant’s prospects worse than bad feng shui. Restaurants, understandably, get furious when they feel wronged—especially by vague, hostile, or outright malicious reviews. In response, they often appeal to Dianping, asking for these ratings to be reconsidered and (hopefully) wiped.
Here’s where it gets interesting: Dianping doesn’t rule unilaterally. Instead, they crowdsource judgment through something very much like Twitter’s Community Notes system.
When a rating is appealed, the platform:
- Notifies both the restaurant and the reviewer to submit “evidence.”
- Pushes the case, along with all supplementary notes, to a pool of community judges.
- The judges then vote whether the rating is “appropriate” or “inappropriate.”
Let’s get nerdy and think about it mathematically.
Suppose there’s some unknown true “appropriateness” of a disputed rating, call it
Each community judge gives a noisy binary signal
where
$$ \Pr[s_i = 1\mid r] = q(r) $$and naturally, $q(r)$ should be increasing in $r$ — meaning, the more appropriate the rating actually is, the more likely a random judge will vote “appropriate.”
From Dianping’s perspective, the job is to use a limited number of judge votes to best infer $r$, reaching a sufficiently high-confidence decision. It’s a classic Restless Multi-Armed Bandit (RMAB) setup… but: not only does the platform care about precision (i.e., minimizing false positives/negatives), but also speed. A slow verdict is bad for everyone—reviewers, restaurants, and diners alike.
In practice, you can already see this system evolving: more controversial ratings (i.e., ones that get split opinions among early judges) seem to get more judges assigned to them.
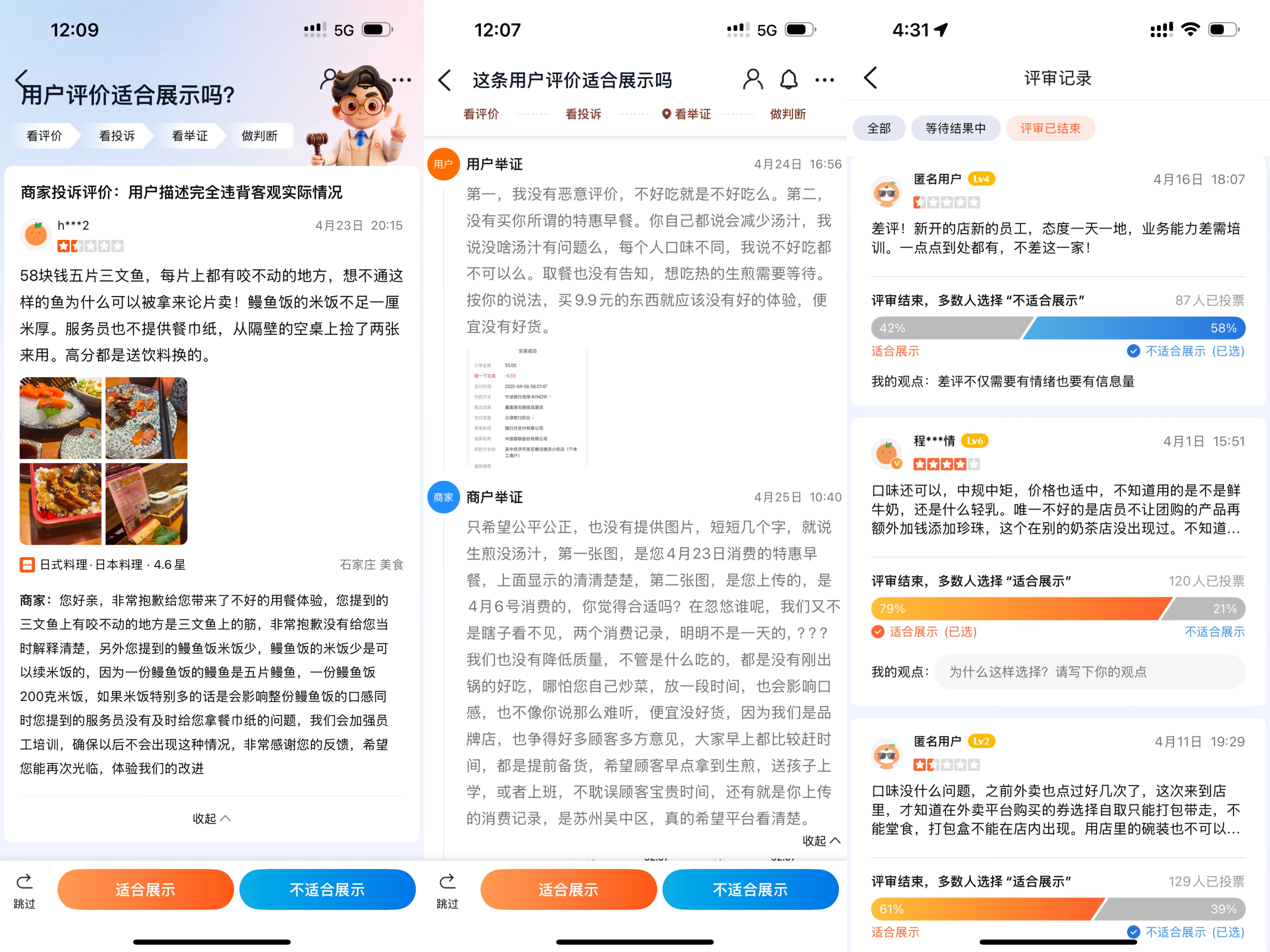
The pipeline of community judges’s weighings
If you squint at it, this could be a fantastic Contextual-RMAB problem in operations management:
- Different ratings have different underlying controversy levels.
- Judges have different (unknown) reliabilities.
- Time pressure matters.
Lmk if you want to work on it with me.
Meanwhile, for the rest of us, it’s a reminder that even deciding whether a ¥19 wonton shop deserves a 2-star review has quietly turned into a probabilistic social experiment—with algorithms lurking in the background, judging our judges.