
i kinda liked it
SHERLOCK is an AI-written code detector. Given a piece of input code string $\mathbf s$, labelled with either human or AI, for example:
Human written:
#include <algorithm> #include <iostream> #include <vector> using namespace std; int main() { vector<int> line; int pro; for (int i = 0; i < 10; ++i) { cin >> pro; line.push_back(pro); } sort(line.begin(), line.end()); for (int i = 9; i > 6; -i) { cout << line[i] << endl; } return 0; }GPT written:
// Problem Name: Cheater's Nim // Input: int N; int a_1; int a_2; ... int a_N; // Output: int cheater_stones; // Logic: int main() { cin >> N; cin >> a_1; cin >> a_2; ... cin >> a_N; // Initialize variables int cheater_stones = 0; int remaining_stones = 0; // Loop through all piles for (int i = 1; i <= N; i++) { // If there are no stones left in the pile, skip it if (a_i == 0) continue; // Compute the maximum number of stones the cheater can take from this pile int max_stones = min(a_i, remaining_stones); // Update the number of remaining stones remaining_stones -= max_stones; // Update the number of stones the cheater has eaten cheater_stones += max_stones; // Print the number of stones the cheater has eaten so far cout << cheater_stones << endl; // If there are no more stones left, break if (remaining_stones == 0) break; } // If the cheater has eaten all the stones, print -1 if (cheater_stones == 0) cout << -1 << endl; return 0; }
SHERLOCK maps a given string $\mathbf s$ into a predicted label $\mathcal S (\mathbf s) \to \{0, 1\}$. Naturally, we would want a detector as astute as Sherlock Holmes so that he can identify, for a given code input, the exactly true state of its original author, pinned down lines to lines. For example, sometimes a piece of code can be co-authored by both GPTs and assembled by the programmer himself. But in this research, we narrow down to study a binary differentiation task to detect AI-written code, out of educational content. That is to say, we focus on beginner-level, task-specific coding problems and the answer, like the preceeding two examples.

The code is generated by copy-and-paste prompting a GPT model, with the output being copied and pasted to submit as some homework solution. This scenario corresponds to a realistic problem faced by educators in introductory programming courses - when instructors assigned homeworks but students just copy and paste GPT’s answer.
The conjecture backbone of the technique is proposed in 2023 by Mitchell et al. [1], that AI-generated text exhibits local optimality in the likelihood curvature of its source model, meaning it tends to have lower probability or higher loss after perturbations. Human-written text, on the other hand, does not exhibit this property - perturbation and original text’s probability log-likelihood are more stable.
Btw, perturbation means, randomly masking some words (tokens) and then use another GPT model to fill in the blanks. Like this:

how perturbation works.
We re-designed a tokenize-and-perturb method tailored for codes, then replicated Mitchell’s paper’s result and found that for codes, similar rules apply
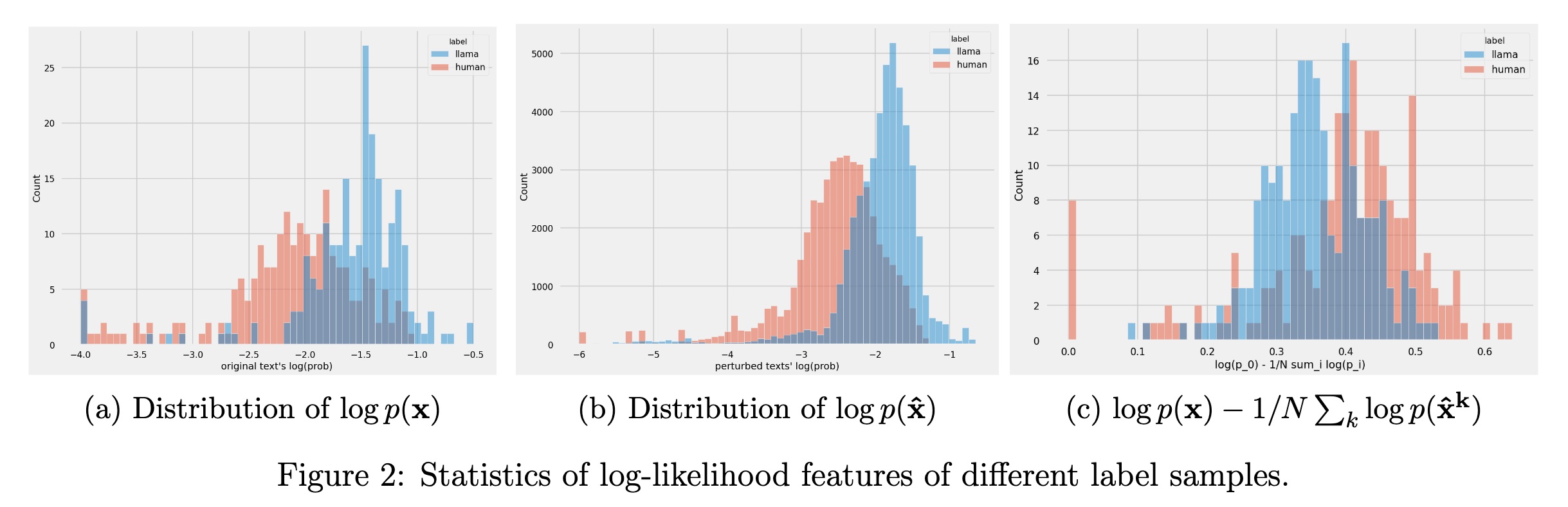
Given any piece of code string, we can obtain its log-likelihood (loss function value) w.r.t. a language model. For an original input code string x and its perturbation, the log(p) distribution varies statistically when according to its label (human/AI).
Now then, everything is ready and we can implement SHERLOCK. For a piece of code $\mathbf s_0$, it is perturbed $N$ times to obtain $\{\hat {\mathbf {s_i}}\}_{i = 1}^N$, and fed into a “grading” language model to obtain its loss function probability log-likelihood $p(\hat {\mathbf s_i})$ - i.e. the probability of such sentence in view of the grading language model. After this manipulation, we obtain
$$ \mathbf p(\mathbf s) = \begin{bmatrix} p(\mathbf s_0)\cr p(\mathbf {\hat s_1})\cr ...\cr p(\mathbf {\hat s_N}) \end{bmatrix} $$This probability vector is then used for subsequent ML binary classifier training.
We built a small dataset ourselves - cleaning up a Kaggle dataset of codeforces competition to obtain the problems and the solutions submitted. The solutions are in c++ and labelled as human-written since the date of the dataset is prior-GPT (2019). The problems are then used to prompt 70-b llama to obtain AI-labeled codes. Eventually, our dataset consists of $M = 216$ samples for both labels respectively. And here’s the result:
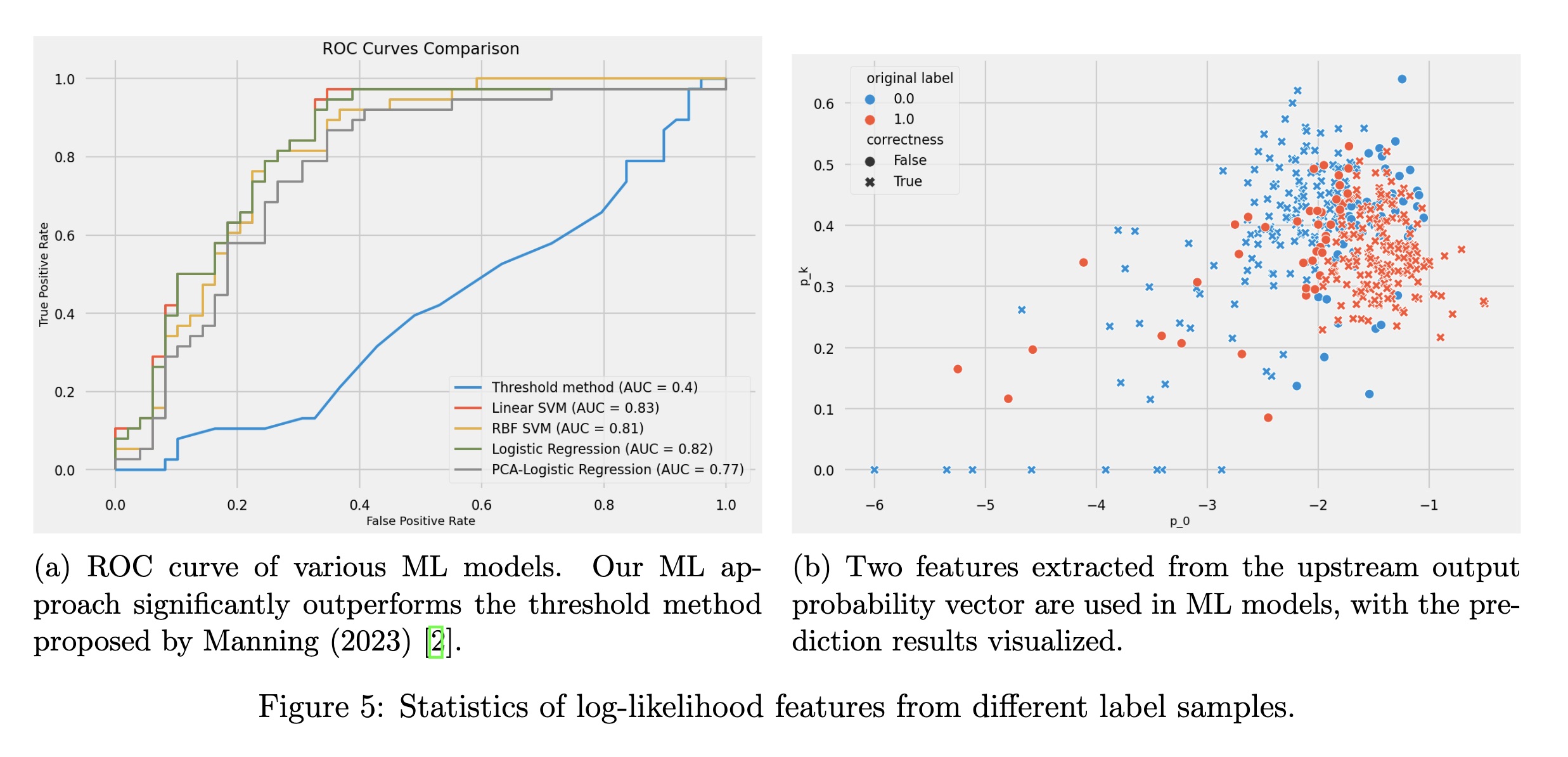
results obtained on the test set. it’s actually pretty neat for this small test out. we also tested Mitchell’s original threshold-based classification method (blue line on the left). it turns out that a little bit machine learning boost a long way.
Finally, the code is here, and, the main paper that we referred to:
[1] Eric Mitchell et al. “DetectGPT: Zero-Shot Machine-Generated Text Detection Using Probability Curvature”. In: Proceedings of the 40th International Conference on Machine Learning. ICML’23. 2023.